Neurips Wrapup Post 1
Neurips 2022 - A wrap up post #1

Neurips 2022 has just finished - and it was a great conference! It was my first proper conference since Covid, and it was so much fun. I don’t go to Neurips to present, but rather to absorb. Over time, it has become part of my yearly calendar that I really look forward to. It’s a chance to reconnect with what is happening at the edge of deep learning.
There was so much interesting work on display at the conference, and here are some initial highlights from the poster sessions. I have so many notes that I suspect there will be one or two more posts in the future.
Highlights
-
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding - This is probably the most noteworthy paper in the conference - it’s SOTA results on image generation which used a pretrained large language model (LLM) were the harbinger of a whole slew of incredible results in generative modeling using diffusion models.
-
Flexible Diffusion Modeling of Long Videos - As soon as the first DALLE image generation results came out, and certainly after stable diffusion, video has been the next fronteir both users and researchers have been waiting to be breached. Up to now, snipets of a few frames with some consistency were possible. Three works at Neurips this yeah show significant progress, and this is one of them. By flexibly choosing which frames to condition on and which frames to generate, this paper proposes a method that makes coherent long video (semantically and temporally) possible. This was also the coolest poster presentation as it included 8 ipads hung onto the poster! The other two works were GAUDI: A Neural Architect for Immersive 3D Scene Generation (presented super well Miguel Angle Bautista) and Generating Long Videos of Dynamic Scenes
-
Training language models to follow instructions with human feedback - Large Language Models are everywhere nowadays and this work will only make them more popular. InstructGPT is no doubt part of the magic of ChatGPT. Re-inforcement learning from human feedback is applied to a Large Language Model to algin the results of the language model to human preferences. Specifically, three steps happen: 1. in supervised pretraining demostrators take a prompt and show what should have been generated, 2. a reward model is trained by having labelers rank different generations by the finetuned model from step 1, 3. the reward model is used in an RL setting (policy gradient optimization) to further fine-tune the language model to align with human preferences. This work has the potential to have a significant impact and could be the basis for using language models in industry applications.
Interesting:
-
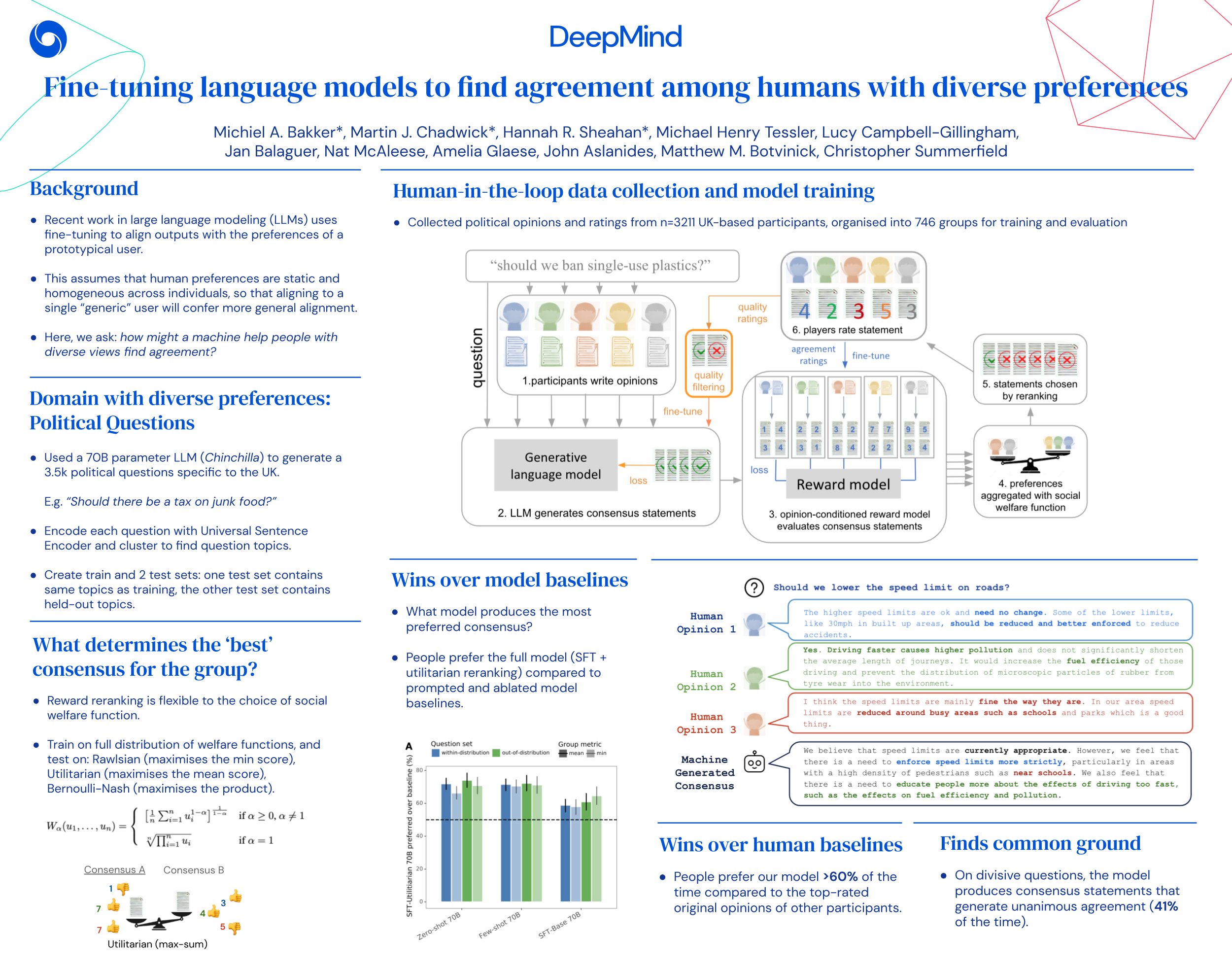
Fine tunning on human preferences, a fascinating paper and poster from DeepMind. It explores how using a large language model you might model (find) agreement within humans with diverse preferences, even better than if humans tried to find this alignment. This work has applicabilty on community moderation
-
Decoupled Context Processing for Context Augmented Language Modeling. This paper proposes a simple but efficient way of retriving context for, context augmented tranformers. Specifically, decoupling the retrieval of context during inference time and by doing so, enabling the pre-computation of that context.
-
STaR: Bootstrapping Reasoning With Reasoning - There was plenty of work exploring chain of thought agumentations: different flavour of providing of generating an explanation or rationale for a given prediction, or training or fine-tunning with scratch-pads that include the chain of thought to get to an answer. This paper introduces a way to boot-strap rationales directly from a large language model. They few-shot prompt a large language model to self-generate rationales and refine the model’s ability further by fine-tuning on those rationales that lead to correct answers.
-
Block recurrent transformers and Jump Self Attention - two interesting posters. Block recurrence allows models to capture relationships in input that is much longer than what sequence length allows for in current transformers. It does this by running sliding window attention over blocks of input and state vectors. State vectors are calcualted over the last segment of blocks (just like old RNNs).
-
UQ360 - An uncertainty quantification toolbox presented by IBM. Uncertainty quantification can be either intrinsic, a model creates some for of uncertainty measure (e.g. gaussian mixture models) or extrinsic, a method external to the modeling procedure estimates uncertainty post-hoc. This workshop talk and the package described at the end of it, provded a toolbox for providing uncertainty quantification to most models. I’m keen on learning much more about this, as providing an uncertainty measure as a key deliverable of any ML work should become standard and it is far from being the case right now
-
Diffusion Models as Plug-and-Play Priors - Really interesting work that advances conditioning diffusion models by trating the diffusion model as a module that knows about priors. There are some neat examples in image segmentation but this is a highlight for me because of what I think might be it’s applicability in making learned distributions (over types of image space for instance) usable in a modular way
-
SAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos - Building on Slot Attention, describes work to model object segmentation and tracking without supervision (ground truth or labeled segmentation maps) for Video. The core premise is the few slot attention buckets fight to explain each pixel in each frame in a video. This competiton leads to salient object, especially over time
{kind=link}
Other interesting work:
- Generalised Mutual Information for Discriminative Clustering
- Focal Modulation Networks - a clever way to take the intution of focal attention to make cheaper transfoermer based vision models
- Work exploring cheaper inference: 8 bit quantisation (code), 8bit quantisation at scale DeepSpeed, Flash [Attention](https://neurips.cc/media/PosterPDFs/NeurIPS 2022/54008.png?t=1669572827.0747266), Binarised quantisation